{kind=link}
Okay, so today I wanted to mess around with something called a “weighted F1 score.” I’d heard of it before, but honestly, never really got it, you know? So, I figured, let’s dive in and see what this thing is all about.

First, I needed some data. I grabbed a simple dataset – I think it was about classifying different types of… something. It doesn’t really matter, the point was to have some classes that were imbalanced. Like, way more of one type than the others. That’s where the “weighted” part comes in, I think.
I loaded up my trusty Python and the usual suspects: pandas for the data, scikit-learn for the machine learning stuff. I did a quick split of the data into training and testing sets. Nothing fancy there, just the regular train_test_split thing.
Start to building Model
Now, for the model, I kept it super simple. A basic logistic regression. I wasn’t trying to win any awards for accuracy, just wanted something to play with the F1 score. So, I fit the model on the training data, and then predicted on the test data. Boom, done.
Now, the fun part. I used classification_report from scikit-learn. It’s a neat little function that spits out a bunch of metrics, including precision, recall, and… the F1 score! And it gives you different versions of the F1 score: “macro,” “micro,” and “weighted.”
- Macro: simple means every type equally.
- Misco:Considered TP、FP、FN, so it will be influnced by imblance.
- Weighted: it means that the more data for a type, the greater its impact.
I looked at the numbers, and it started to make sense. The “macro” average treated all classes equally, even the tiny ones. The “weighted” average, though, it gave more importance to the classes with more samples. That’s means it is useful to process imblance dataset.
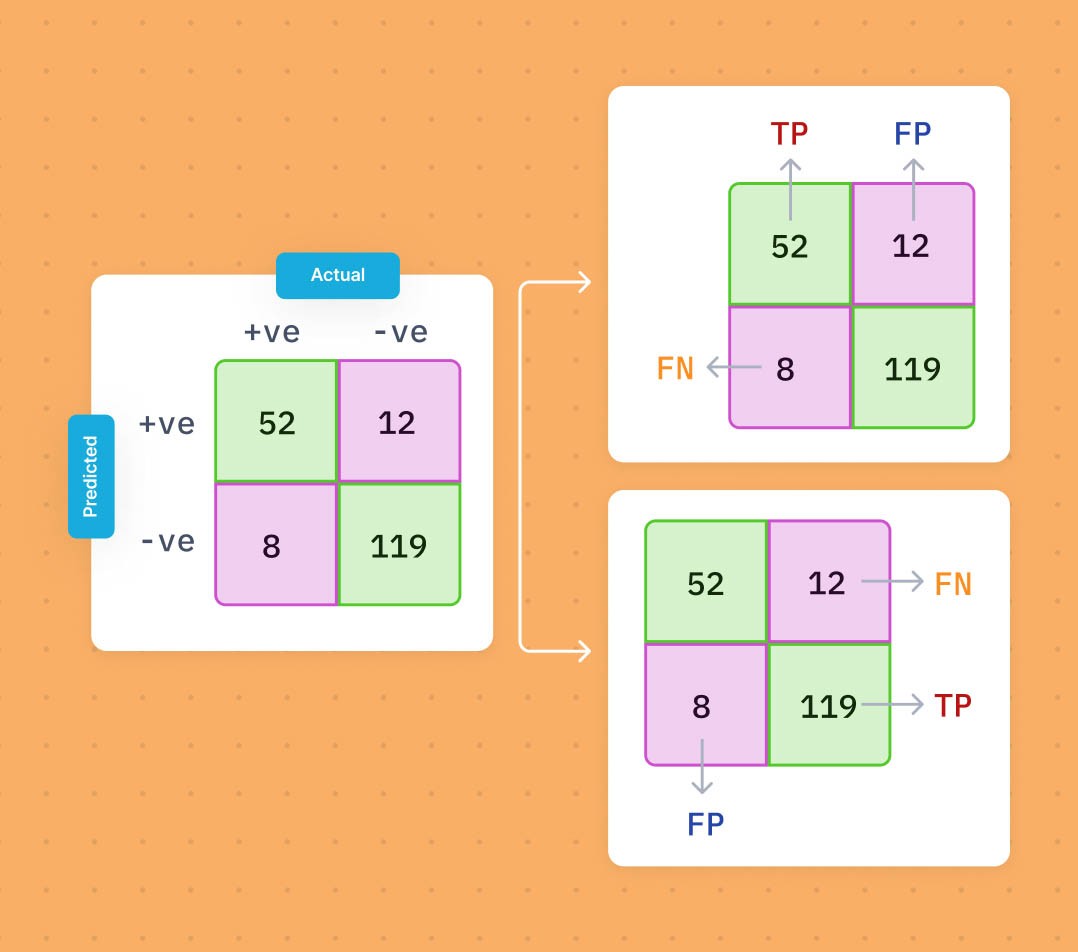
So, basically, the weighted F1 score is useful when you have imbalanced classes, and you care more about the performance on the classes with more data. It’s like giving them a bigger say in the overall score. Makes sense, right?
I played around with it a bit more, maybe changed the model a little, looked at the different F1 scores again. It was a good little learning session. I feel like I finally get what the weighted F1 score is and when it might be useful. Another tool for the toolbox!